Всі статті

- Перша робота
До чого готуватись DevOps-фахівцю перед першим on-call
May 15, 2026
~ 8 хв
У світі DevOps сервіси не перестають падати після завершення робочого дня. Якщо інцидент стається о 3-й ночі, хтось має підняти прод назад. Саме тому on-call чергування стали поширеною практикою у DevOps, SRE та інфраструктурних командах.
У цій статті розберемо: як працюють ці чергування, з якими труднощами можуть зіткнутись новачки, як до них підготуватись і чи є on-call частиною здорової культури компанії.
Що таке on-call і хто з цим зіштовхується
On-call — це формат чергування у позаробочий час, під час якого спеціаліст має бути готовим швидко відреагувати, якщо з продуктом, сервісом або інфраструктурою щось піде не так.
Статистика свідчить, що ймовірність нічних алертів безпосередньо залежить від вашого напряму. Ось як розподілилася частка фахівців, які мають on-call чергування, за спеціалізаціями:
- SysAdmin 48,6%
- Database administrator 42,9%
- Technical Support 37,5%
- DevOps Engineer 30,3%
- Security 29,2%
- Data / Big Data Engineer 19,9%
- QA 9,5%
Ознака здорової on-call культури — справедлива компенсація за працю в неробочий час. Проте, за даними DOU, у 56% випадків українські фахівці не отримують жодної надбавки. Найчастіше це стосується системних адміністраторів, Data Engineers та частини розробників.
Якщо компенсація все ж передбачена, зазвичай це фіксована сума. Значно рідше компанії використовують погодинну оплату або бонуси за усунення проблем.
Як влаштований процес on-calls
Найчастіше on-call процес виглядає так:
- система помічає проблему;
- надсилає алерт;
- інженер на чергуванні отримує сповіщення;
- перевіряє інцидент;
- шукає причину проблеми;
- намагається якомога швидше відновити роботу сервісу.
Для багатьох новачків такі чергування є доволі тривожними. Насамперед через страх пропустити алерт, не зрозуміти у чому причина інциденту або залишитись сам на сам із проблемою посеред ночі.
Важливо розуміти: on-call не означає, що інженер має героїчно вирішувати абсолютно все самостійно. У більшості компаній для критичних ситуацій існують escalation policy — правила, які визначають, хто і коли долучається до інциденту, якщо проблему не вдається швидко вирішити.
Щоб on-call не викликав панічних атак у спеціалістів, команди зазвичай використовують:
- моніторингові системи та системи сповіщень;
- покрокові інструкції для типових інцидентів (runbooks/playbooks);
- документацію для типових проблем;
- канали реагування на інциденти у Slack або Teams;
- процеси передачі чергування між змінами.
Водночас on-call — це не лише про реагування на критичні інциденти. Частина роботи DevOps та SRE-команд полягає у тому, щоб поступово зменшувати кількість нічних алертів і рутинних проблем через автоматизацію.
Особливості on-calls для DevOps-фахівців
Позаробочі чергування у сфері DevOps часто відрізняється від класичної технічної підтримки. Зазвичай вони тісно пов’язані з підтримкою інфраструктури, CI/CD процесів, cloud-сервісів та стабільної роботи production-середовища.
Під час on-call DevOps-фахівці можуть стикатись із:
- падінням сервісів або контейнерів;
- проблемами у Kubernetes-кластерах;
- збоями CI/CD pipeline;
- перевантаженням серверів;
- проблемами з cloud-інфраструктурою;
- системами моніторингу та сповіщень;
- мережевими або DNS-збоями;
- проблемами після оновлення сервісу.
У багатьох компаніях on-call також включає troubleshooting production середовища та координацію каналів реагування разом із SRE, back-end або platform-командами. Тому такі чергування вимагають не лише технічних знань, а й вміння швидко реагувати та працювати під тиском.
Червоні і зелені прапорці on-calls у компаніях
On-call процеси можуть сильно відрізнятись залежно від компанії. Саме тому важливо ще на етапі співбесіди запитати про on-call культуру в компанії та звернути увагу на червоні й зелені прапорці процесу.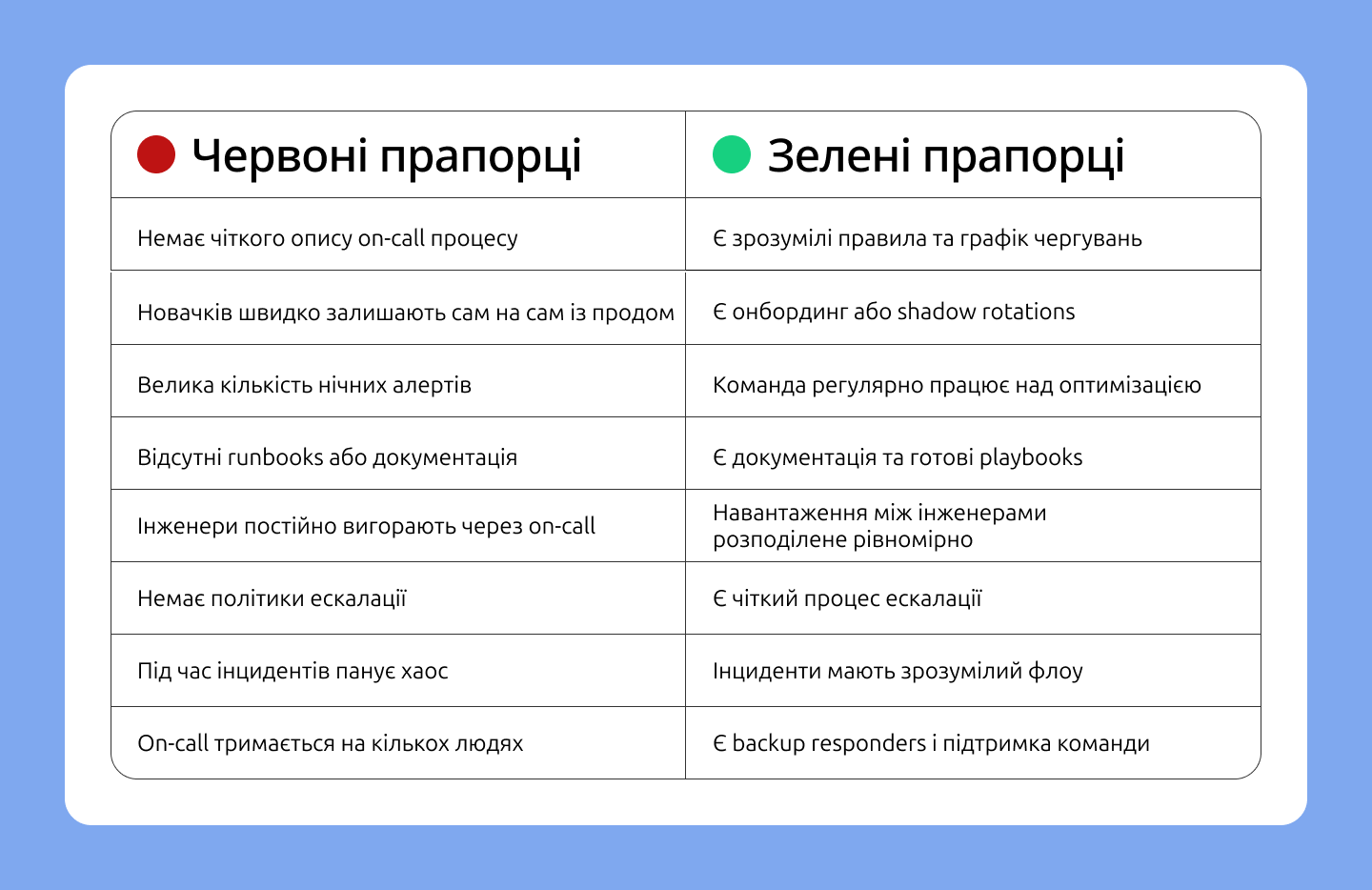
Замість висновків
Будь-хто погодиться, що найкращий on-call — це нудний on-call. Саме так зазвичай виглядають процеси у компаніях, де більшість проблем намагаються попередити ще до того, як вони перетворюються на нічний інцидент.
Так, перші чергування можуть лякати новачків — і це абсолютно нормально. Робота під тиском у будь-який час доби справді може бути виснажливою, але в командах зі здоровими процесами інженер не залишається з проблемами сам на сам.
Анастасія Хітрова
500+ фахівців вже чекають на ваш офер
Знайдіть свого ідеального DevOps-інженера. Це швидше, ніж ви думаєте.
Гарячі вакансії
Вас також зацікавить
5 ознак, що час шукати нову роботу
Звичайна втома чи реальний привід оновити резюме? Дізнайтеся, які неочевидні маркери вказують на те, що компанія більше не сприяє вашому розвитку.
Виклики найму та нові вакансії квітня: дайджест NETFORCE Jobs №2
Аналізуємо головні виклики найму 2026, ділимося дієвими стратегіями для кандидатів і компаній та показуємо, як спростити процес пошуку з NETFORCE Jobs.
Мікрошифтинг в IT: що потрібно знати про цей формат роботи?
Мікрошифтинг — новий тренд на ринку праці. Читайте, як розбиття робочого дня на блоки допомагає підвищити продуктивність і уникнути професійного вигорання.